From Incident Counting to SLIs: How DigitalOcean Rethought Availability
- Published:
- 11 min read
Our journey to truly understand our customer experience began with a hard look at our internal availability numbers at the start of 2025. We saw something uncomfortable: the numbers didn’t match our customers’ reality. Our monthly availability oscillated between 99.5% and 99.9%. Those peaks and valleys depended more on whether we declared a high-severity incident that month than on how the platform was actually performing. Customers were still experiencing issues and opening escalations, but the metric didn’t reflect customer availability.
The previous internal measurement served us well in our early days, but its limitations became evident as DigitalOcean expanded. Our incident-based approach treated any declared incident as a total outage and anything below the severity threshold as invisible. This created a structural trap: we couldn’t expand coverage to include lower-severity issues without artificially destroying our availability number, because the formula would count every minute of a partial degradation as a full platform outage.
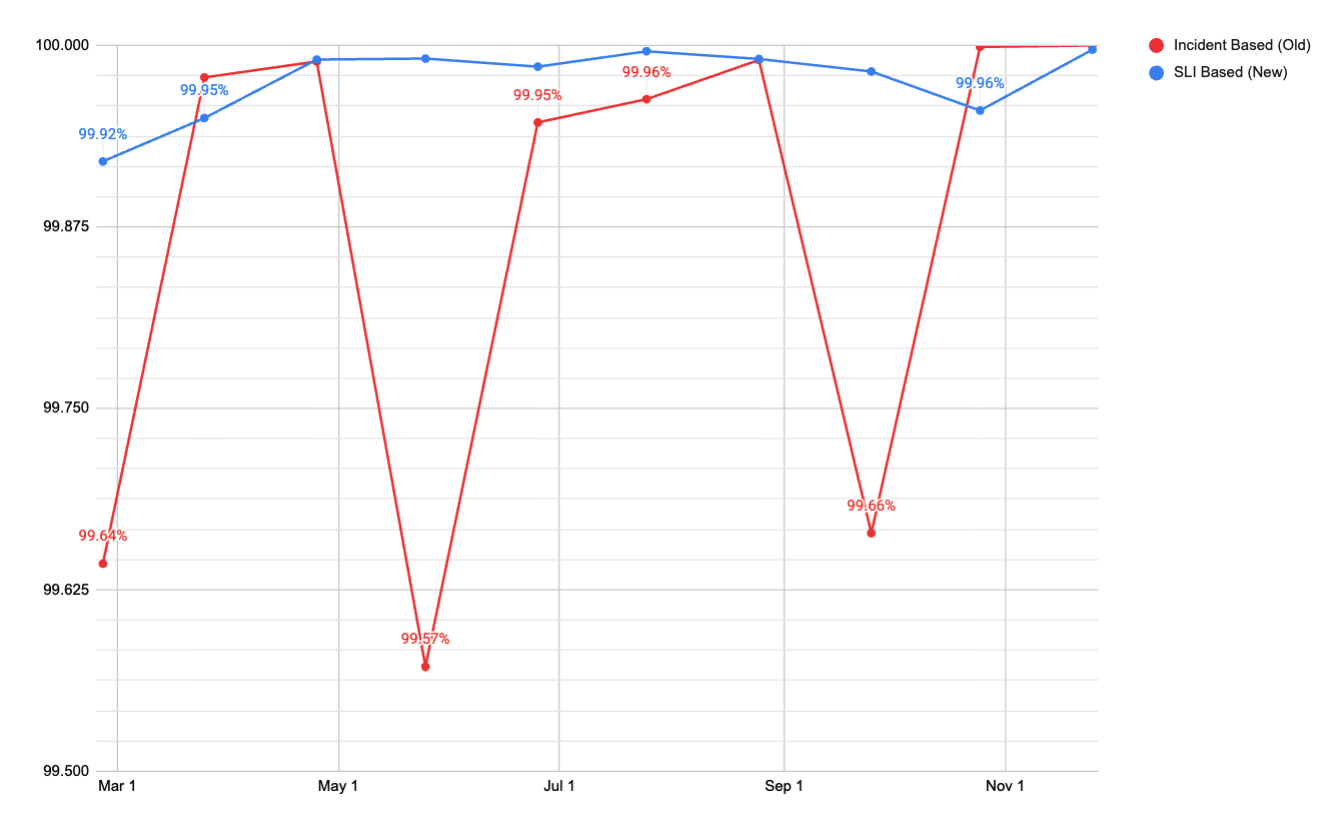
The chart above shows monthly platform availability using both methodologies over the same time period. The incident-based (old) swings between roughly 99.5% and 99.9% month to month. The SLI-based metric (new) holds consistently at 99.95% or above. The old metric was measuring noise, while the new metric measures actual availability signals.
This isn’t a problem unique to DigitalOcean. Any platform that measures availability by counting incident minutes against total calendar time will eventually hit the same wall. The incident-based metric was both too generous and too punitive, depending on where the line was drawn.
Thisarticle walks through the operational framework we built to replace that system, the architectural decision to split the measurement into Control Plane and Data Plane, the two different SLI methodologies we use for each plane, the Prometheus recording rules and multi window alerting that make it operational, error budget policies that now drive engineering priorities, and how this framework is extending to newer product lines including our GPU Droplets and Agentic Inference Cloud products.
The Old Methodology
The original formula was simple and was measured weekly based on incident duration:
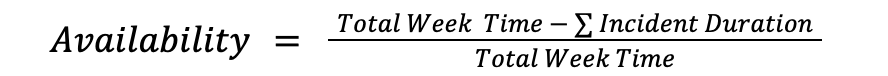
If no incident was declared in a week, then availability was 100%. If an incident lasted two hours, we subtracted those 120 minutes from the total and got our number. This methodology served us well initially, but it had three main problems as our platform and product offering grew:
- During an incident, it assumed 100% of the product was down for 100% of customers. Outside of an incident, it assumed everything was fine. There was no way to represent partial impact.
- The global availability number was the mean across around 30 products. There was no volume weight. A product with a few hundred daily requests pulled to the average as much as our Droplets or Spaces products.
- The same availability formula was used for every DigitalOcean product offering, even if it was not the best representation of their uptime.
Splitting Our Measurement: Control Plane vs Data Plane
The first decision was to stop treating all availability the same. A slow API response when creating a Droplet is a different kind of failure than a Droplet being inaccessible. One is an inconvenience, the other is active customer pain. Lumping them into a single number was hiding signal in noise.
We split measurements into two planes, each with their own SLI methodology.
Control Plane
The control plane covers the orchestration layer, including API calls like create_droplet or update_firewall and Cloud Panel operations. The SLI is the success rate for valid requests:
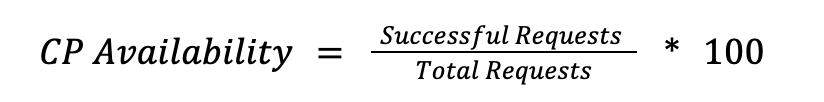
We count only server errors (5xx) as failures. Client errors (4XX) stay in the denominator but are excluded from the failure count, since a malformed request from a user isn’t a platform reliability signal. If the Control Plane degrades, users see errors in the API or Cloud Control Panel for CRUD-type operations, but their running workloads (Agents, Serverless, GPU Droplets, Databases) are uninterrupted.
Data Plane
The data plane covers the live product instances: running CPU and GPU Droplets, DOKS Clusters, Spaces Buckets, Serverless Inference endpoints, AI agents. Measuring Data Plane is more nuanced than Control Plane because different products fail in fundamentally different ways. There is no single formula that fits all of them.
For products where availability means “the resource exists and is healthy,” regardless of the active usage, we use resource minutes.
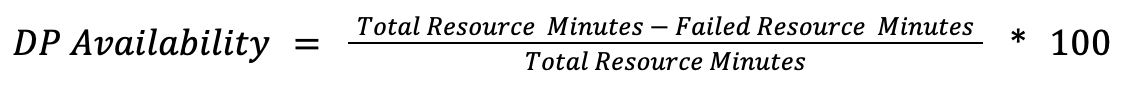
A resource minute represents one resource being available for 1 minute.
For products where the Data Plane serves requests directly, we use the same request-based approach as in Control Plane, but measured at the serving layer:
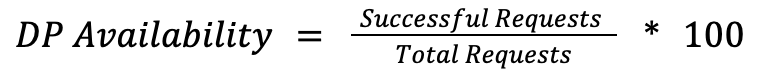
Below are some examples on how this looks on practice:
- Droplet Networking (resource-minutes): A Droplets network is considered available when all connectivity probes pass simultaneously. The data path reachability, public routing (ipv4 and ipv6), management interfaces, among others. It’s a logical AND, which means all probes must pass. If any single probe fails, that minute counts as a failed resource-minute for that droplet.
- DOKS (resource-minutes): A cluster is available when 3 conditions are true simultaneously. The Kubernetes API is reachable, etcd has an elected leader and the API server is serving healthy responses (non-5XX). If any of them fails outside of a planned maintenance window, the cluster scores 0 for that minute. Maintenance windows are excluded, so planned operations don’t count against availability.
- Spaces (request-based): Availability is measured as the ratio of non-5xx responses to total requests at the storage load balancer layer. Rate-limiting responses (503s) are excluded from the failure count, since they represent intentional throttling and not a platform failure.
The definition of a failed state varies by product because a Droplet with broken networking, a DOKS Cluster with no etcd leader, and a Spaces object that can’t be retrieved are all “unavailable,” but they fail in completely different ways. Each product defines failure in terms of what the customer actually experiences.
Here’s how the two planes fit together:
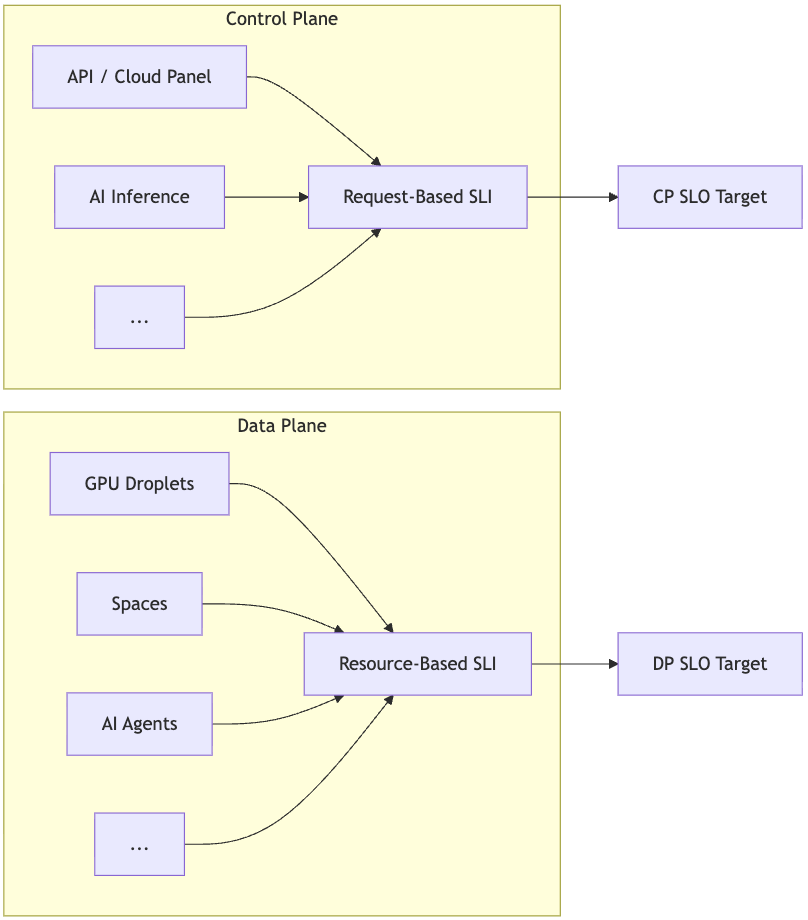
The separation of control and data plane gave us two things we didn’t have before. First, we could set different SLO targets per plane, because the tolerance for a failed API call and inaccessible storage is not the same. Second, we could make meaningful comparisons with how other cloud providers structure their SLOs, which follow this same control plane/data plane distinction.
Magnitude matters
With the Control Plane and Data Plane defined, the next problem we faced was aggregation. We operate across multiple regions with different traffic volumes. A failure in a small data center (DC) and a failure in our busiest DC are not the same, and our metrics needed to reflect that.
Control Plane
We used a weighted request average by volume. This means that we sum all raw success and total counts across all DCs before calculating the ratio. A DC handling only 20% of traffic contributes only 20% of the signal, meaning no manual weighting is needed.
Example using NYC3 and TOR1:
| NYC3 | TOR1 | |
|---|---|---|
| Successful Requests | 593,439,326 | 148,458,075 |
| Total Requests | 593,498,661 | 148,532,291 |
| Availability | 99.99% | 99.95% |
Unweighted percentages: (99.99% + 99.95%) / 2 = 99.97%
Summing raw counters: (593,439,326 + 148,458,075) / (593,498,661 + 148,532,291) = 741,897,401 / 742,030,952 = 99.982%
TOR1 handles only 20% of the total traffic, but without weighting, it pulls the global number down as if it handled half.
Data Plane
We needed to know how many resources exist and whether they are healthy. This is product agonistic, but in general, we combine 2 signals per product.
Example using Managed Databases in NYC3 and AMS3
| NYC3 | AMS3 | |
|---|---|---|
| Total Requests | 400 | 500 |
| Availability | 99.9% | 99.95% |
Unweighted average: (99.99% + 99.95%) / 2 = 99.97%
Magnitude-weighted: (99.99 × 4,000 + 99.95 × 500) / (4,000 + 500) = (399,960 + 49,975) / 4,500 = 449,935 / 4,500 = 99.985%
AMS3 has only 11% of the total instances, but without weighting, the global is pulled down.
The weight problem compounds as we add more regions to the mix. Every DC gets an equal vote regardless of how much traffic or how many instances it handles. At 10+ regions, the global number can be dominated by the smallest DCs rather than by where your customers actually are. Weighting by actual volume eliminates this entirely.
From Raw Metrics to Recording Rules
With the math defined, we hit a practical problem: querying raw high-cardinality data over 30-day windows in Prometheus doesn’t work. At our scale, those queries would either time out or put load on our time series DBs.
The solution to overcome this was to add Prometheus recording rules. Instead of computing availability at query time, we configured recording rules at fixed intervals to store the data points as a new time series. This turns expensive 30-day aggregations into cheap lookups: instead of computing availability from raw data over a month, we query pre-computed 1-hour data points.
We follow a standardized naming convention across all services following the pattern sli:
Example Control Plane
None- record: sli:global:control_plane_services:availability:rate5m
expr: |-
(
sum(rate(edge_http_requests_total{status!~"5.."}[5m])) by (service)
/
sum(rate(edge_http_requests_total{}[5m])) by (service)
)
- record: sli:global:control_plane:service_availability:rate1h
expr: |-
# Same query with [1h] window
Example Managed Databases Data Plane
None- record: sli:global:data_plane:dbaas_availability:rate1h
expr: |-
(
count(count_over_time(dbaas_cluster_uptime[1h]))
*
avg(avg_over_time(dbaas_cluster_uptime[1h]))
)
/
count_over_time(dbaas_cluster_uptime[1h])
This is the magnitude-weighted formula from the previous section as a recording rule: instance count times average availability, normalized by total instance-time.
Product Journeys
A product doesn’t exist as a single service. Our Kubernetes service, for example, spans from the edge through API, auth, and core services down to the reconciler. If any one of those degrades, the customer feels it.
To capture this, we built Product Journeys. A Product Journey maps the full service dependency chain for a product:
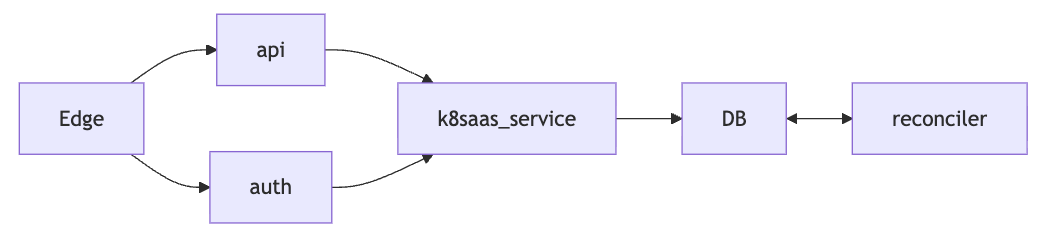
Each box in the diagram has its own availability SLI. The edge is our primary signal because that’s where customers actually interact with the product. The internal services behind the edge give us the breakdown, and when edge availability drops, we can trace which component in the chain caused it.
Multi Window Multi Burn Rate Alerts
With recording rules producing availability SLIs, the next step in our list was alerting. We started with a single burn rate alert on a fixed one-hour window. If the error rate over the last hour was high enough to threaten our SLO, we paged engineering responders.
This was a great step forward in our adoption of SLO-based alerting, but it had a core limitation. Brief spikes that had already been resolved would trigger pages. Real incidents that were fixed would keep the alert active for up to an hour. In both cases, the on-call engineer had no way to tell whether the problem was still occurring or had already been resolved just by looking at the alert.
To fix this, we moved to a multi-window, multi-burn rate approach, following established practice from the Google SRE workbook. This iteration had two improvements:
Multi-window pairs a long window with a short window. The long window confirms statistical significance, while the short window confirms the issue is happening right now. This solves the false page and lingering alert problem in one move.
Multi-burn-rate adds a second tier to catch slower degradations. A single high-burn rate threshold only catches acute failures. A service slowly leaking errors over hours would fly under that threshold while still eating through the error budget.
Example definition:
None- alert: GlobalAvailabilityImpact
expr: |-
(
# Fast burn: 14.4x
(
_# Error rate (1 - availability) exceeding 14.4x the budget rate_
1 - sli:global:control_plane_services:availability:rate1h > (14.4 * 0.0005)
and
1 - sli:global:control_plane_services:availability:rate5m > (14.4 * 0.0005)
)
or
# Medium burn: 6x
(
1 - ssli:global:control_plane_services:availability:rate6h > (6 * 0.0005)
and
1 - sli:global:control_plane_services:availability:rate30m > (6 * 0.0005)
)
)
Error Budgets as Engineering Policy
With SLIs and multi-window alerting in place, we began strictly tracking error budgets. The error budget is the inverse of the SLO: if our target is 99.95% availability, we have a 0.05% budget for failures over the measurement window.
We use a rolling 30-day window rather than a fixed calendar month. Customer pain is cumulative. Their trust in our platform doesn’t reset on the first day of the month, and neither should our budget.
Tracking
Burn rate (which we covered in the previous section): how fast we’re consuming the budget right now. This catches incidents.
Remaining budget: the absolute percentage left. As consumption crosses specific thresholds, the policy response escalates.
Policy
The error budget is not just a reporting metric. It directly influences what teams can ship and how they allocate their time.
We define four zones:
| Area | Green (0-60%) | Yellow (61%-80%) | Orange (81-100%) | Red - (>100%) |
|---|---|---|---|---|
| changes | Operate normally | Caution. Verify no impact on dependencies. | Increase Risk. Pause large rollouts. Standard maintenance and fixes only. | Critical Risk. Paus rollouts. Low-impat maintenance and fixes only. |
| Approvals | Standard | Team Lead or Senior IC review | Staff Eng review | Principal Eng review |
| Resourcing | Normal sprint allocation | Allocate ~50% sprint to reliability | Allocate ~80% sprint to reliability | 100% allocation to reliability and debt. |
This makes the error budget a decision-making tool rather than just a dashboard metric. When a team is in the green, they have room to ship fast and take risks. When they’re in orange, large rollouts stop, and most of the sprint shifts to reliability work. When they hit red, everything stops except stabilization.
Each product line follows these guidelines. When a high-severity incident impacts multiple products and burns through the budget across the board, the policy makes the response automatic rather than a debate about whether to slow down.
From Core to Inference Cloud
Everything described so far was built for core infrastructure products: CPU Droplets, Spaces, Managed Databases. But, the same framework applies directly to newer product lines, including GPU Droplets, our Inference platform, and AI agents.
This was intentional. We built a framework with clear principles (control/data plane split, magnitude weighting, recording rules, multi-window alerting, error budget policy), and applied them to core products first. Once the patterns were proven, extending to new products is a matter of defining the right SLIs, not rebuilding the infrastructure.
GPU Droplets follow the same model as CPU Droplets, wherein the Control Plane SLI tracks API request success for GPU instance lifecycle operations, and the Data Plane SLI tracks GPU instance availability using the same resource-minutes approach. GPU Droplets already have a published SLA.
For the inference platform and AI agents, we’ve started applying the same framework. For example: Serverless Inference availability is request-based at the serving layer: non-5xx responses as a percentage of total requests to the inference endpoint. AI agents follow the same pattern, measuring request success rate for agent-hosted endpoints.
Availability numbers are easy to publish. What’s harder is building a measurement framework that you actually trust, where the numbers reflect what customers truly experience, rather than how you chose to count incidents. That’s what this system gives us, a precise and weighted view of platform health that doesn’t flatter us when things are partially broken and doesn’t punish us for being honest about failures. When we publish SLAs for the Inference Cloud, our internal operational framework will already be in place.
About the author
Related Articles

How we built the most performant DeepSeek V3.2, MiniMax-M2.5 and Qwen 3.5 397B on DigitalOcean NVIDIA HGX™ B300 GPU Droplets
- April 28, 2026
- 6 min read


Beyond the Abyss Project Poseidon’s Quest for Zero-Downtime Reliability
- April 23, 2026
- 7 min read