
Introduction
MiniMax-M2 emerges as a compelling solution for developers, delivering coding and agentic capabilities through a 230B parameter Mixture of Experts (MoE) model with only 10B active parameters. While maintaining competitive performance against frontier models like Claude Sonnet 4.5 and GPT-5, it achieves this with a fraction of the computational overhead, making it exceptionally well-suited for deployment scenarios where cost and latency matter.
Key Takeaways
- Competitive performance in agentic coding
- MoE model, 230B total parameters, 10B active parameters
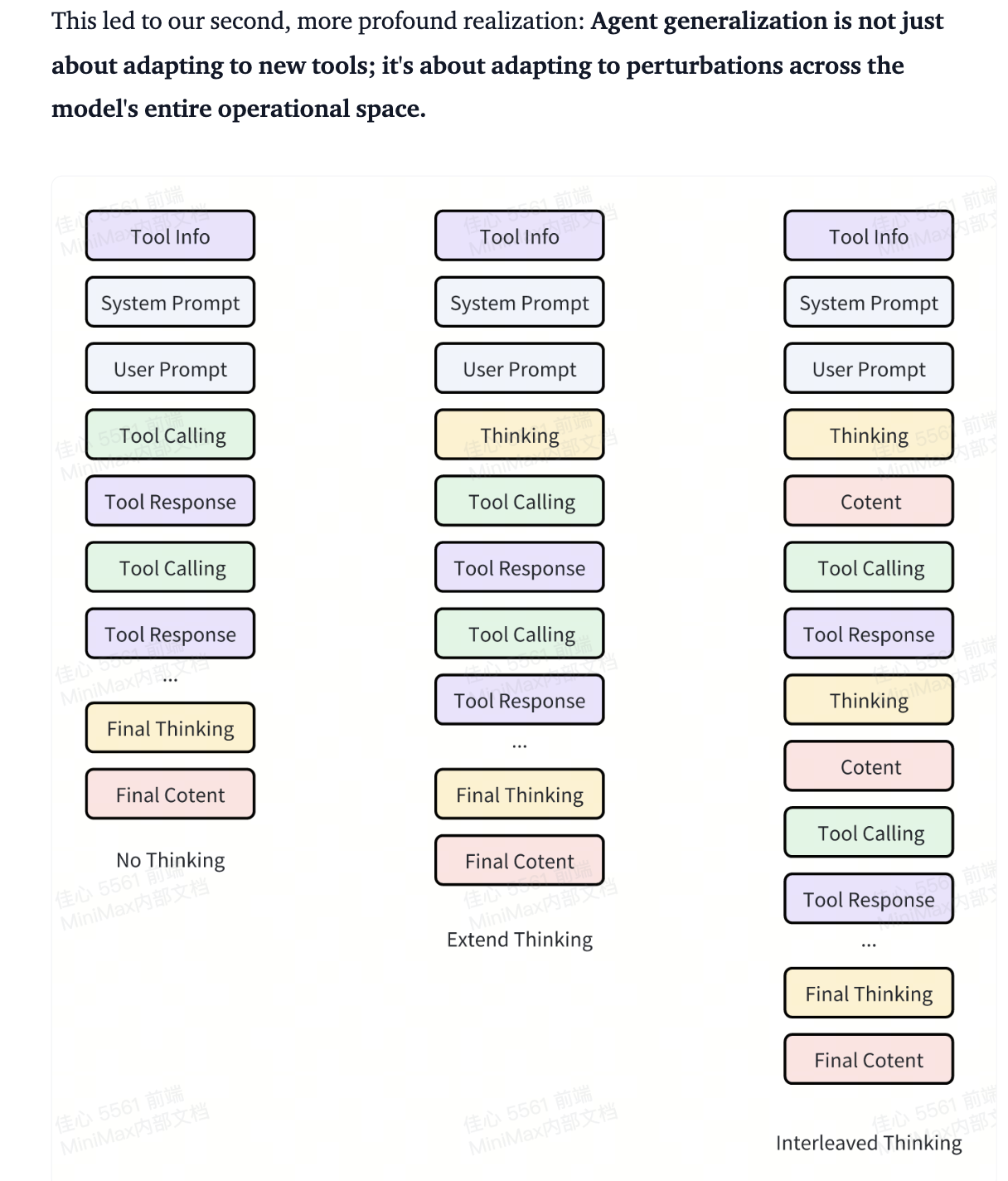
- M2 natively supports an Interleaved Thinking format, where <think> tags separate internal reasoning from the final answer, enabling it to reason between each round of tool interactions.
- The MiniMax Agent, built on MiniMax-M2, is free for a limited time. (Great for testing the model’s potential!)
- You, yourself, can host the model on 8xH200s with DigitalOcean GPU Droplets
Model Overview
| Feature | Developer Value Proposition | Key Metrics/Details |
|---|---|---|
| Agentic Performance | MiniMax-M2 uses <think>…</think> tags to separate its reasoning process from final outputs. This enables the model to maintain coherent thought chains across multi-turn interactions. Excels at complex, long-horizon tasks that require planning, execution, and recovery. Ideal for autonomous agents. | Strong scores on BrowseComp (44.0) and ArtifactsBench (66.8), outperforming several larger models. |
| Advanced Coding | Designed for end-to-end developer workflows, including iterative “code-run-fix” loops and multi-file editing. | Highly competitive on Terminal-Bench (46.3) and SWE-bench Verified (69.4). |
| Tool-Use Proficiency | Built for sophisticated tool integration (shell, browser, search), robust for external data/system interaction. | Dedicated Tool Calling Guide available. Demonstrates strong performance on HLE (w/ tools) and other tool-augmented benchmarks. |
| Superior General Intelligence | Maintains competitive general knowledge and reasoning, ensuring reliability even outside of core coding tasks. | Composite AA Intelligence Score of 61, ranking highly among open-source models. |
Implementation
There are a number of different ways one can run MiniMax-M2 as indicated in their docs.

Given this is a larger model, we’re going to use an 8xh200 cluster.
In your Web Console.
apt install python3.10-venv
v pip install 'triton-kernels @ git+https://github.com/triton-lang/triton.git@v3.5.0#subdirectory=python/triton_kernels' vllm --extra-index-url https://wheels.vllm.ai/nightly --prerelease=allow
SAFETENSORS_FAST_GPU=1 vllm serve \
MiniMaxAI/MiniMax-M2 --trust-remote-code \
--tensor-parallel-size 4 \
--enable-auto-tool-choice --tool-call-parser minimax_m2 \
--reasoning-parser minimax_m2_append_think
pip install vllm fla-core
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "MiniMaxAI/MiniMax-M2",
"messages": [
{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]},
{"role": "user", "content": [{"type": "text", "text": "Who won the world series in 2020?"}]}
]
}'
We see the model output in our web console.

Let’s take a look at the model output:
"content": "<think>Okay, the user is asking who won the World Series in 2020. Let me start by recalling the correct information. The Los Angeles Dodgers defeated the Tampa Bay Rays. That was a significant event because it was during the pandemic, so the season had unique adjustments.</think>The user might be a baseball fan wanting a quick fact, or perhaps someone who has heard about the series and wants confirmation. They didn't mention any specific context, so keeping it straightforward is best. But maybe they're interested in the historical aspect of that win, especially since it was the Dodgers' first title since 1988. Including that detail adds value.I should also note the unusual circumstances of the 2020 season. The COVID-19 pandemic affected everything, with shortened seasons, limited crowds, and other changes. Mentioning these factors could address deeper curiosity about how the event stood out. However, since the user didn't ask for that, I should balance conciseness with relevant context.\\n\\nThe user possibly a casual viewer looking for a quick answer? Or a student working on a project? They might need the answer for trivia or an assignment. Either way, providing the teams and the year, along with the significance of the Dodgers' win, covers the essentials without overcomplicating. No need for excessive details unless they follow up. Keeping the response clear and accurate is key here.\\n\\n<|im-start|>The **Los Angeles Dodgers** won the **2020 World Series**. \\n\\nThey defeated the **Tampa Bay Rays** in 6 games (4-2). This was the Dodgers' first World Series championship since 1988. The 2020 World Series was held in Arlington, Texas, at Globe Life Field (the neutral site) due to the COVID-19 pandemic and its impact on the MLB season. \\n\\nThe decisive game was game 6, played on October 27, 2020, where the Dodgers won 3-1.<|im-end|>"
The output demonstrates MiniMax-M2’s key features:
Interleaved Thinking Format: Uses <think> tags to separate internal reasoning from the final answer.
High-Quality Output: Delivers an accurate, concise answer with proper formatting. Includes essential facts (Dodgers defeated Rays) plus relevant context (pandemic conditions, neutral site, historical significance), demonstrating frontier-level fact retrieval and summarization.
Final Thoughts
If you’re building agentic systems, coding tools, or anything demanding both intelligence and efficiency, try the model and let us know how it performs. The MiniMax Agent, built on MiniMax-M2, is free for a limited time so feel free to test it before hosting the model yourself.
References and Additional Resources
Aligning to What? Rethinking Agent Generalization in MiniMax M2: This resource does a good job of explaining the logic behind MiniMax-M2’s development (i.e. interleaved thinking)
FAQ
What is MiniMax-M2?
MiniMax-M2 is a Mixture of Experts (MoE) model designed specifically for coding and agentic capabilities. While it has a total parameter count of 230B, it is designed to be cost-effective by only activating 10B parameters per token during inference.
What benchmarks highlight its agentic capabilities?
Because MiniMax-M2 was architected from the ground up for agentic tasks (rather than being a general-purpose model retrofitted for them, it outperforms much larger open models on benchmarks like Terminal-Bench (scoring 46.3%) and BrowseComp (scoring 44%).
What is “Interleaved Thinking” and why is it important?
MiniMax-M2 uses specific <think>…</think> tags to separate its internal reasoning process from its final output. This format allows the model to maintain coherent chains of thought across multi-turn interactions, which is essential for complex agentic workflows where reasoning history and context are vital.
Does the model support tool usage?
Yes. The model features a “Tool-First Design” and supports tool calling capabilities, enabling it to identify when external tools are required to complete a task.
What are the recommended hardware configurations for running MiniMax-M2?
Actual requirements vary by use case, but recommended configurations include:
- 4x 96GB GPUs: Supports a context length of up to 400K tokens
- 8x 144GB GPUs: Supports a context length of up to 3M tokens
- Cluster usage: For robust deployment, an 8x H200 cluster is also utilized in demonstration setups
How is the model served?
The model can be served using vllm. Deployment involves installing specific dependencies (like triton-kernels and fla-core) and running the service with flags such as --enable-auto-tool-choice and --reasoning-parser minimax_m2_append_think to enable its specific features.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.