Technical Writer

The AI world has been moving quickly, and each model is going above and beyond model size and context length to build smarter and more capable systems. Alibaba’s Qwen team has taken a major step forward with the Qwen3-Next series. The recent Qwen series introduced new architectural upgrades for better efficiency, faster inference, and smoother context handling. In this article, we’ll dive into Qwen3-Next-80B-A3B-Instruct and explore how its mix of hybrid attention, high-sparsity mixture-of-experts (MoE), and multi-token prediction techniques redefine what’s possible for large language models. We tried testing Qwen3-Next-80B-A3B-Instruct-int4-mixed-AutoRound using DigitalOcean’s Droplet, and the experience was smooth and efficient. The “int4-mixed-AutoRound” is a quantized version of the same model, compressing the model weights to 4-bit integers using a technique called AutoRound. This technique drastically decreases the model size and speeds up model inference with a slight trade-off in accuracy. So if a CPU is used for model testing, a quantized model is a slightly better choice because it is much lighter and faster to run compared to the full model.
Key Takeaways
- Qwen3-Next-80B-A3B-Instruct is a next-generation large language model with 80 billion parameters, designed for high performance on long-context tasks.
- The model introduces Hybrid Attention, High-Sparsity Mixture-of-Experts (MoE), and Multi-Token Prediction (MTP) to improve throughput, cost efficiency, and context understanding.
- It demonstrates strong long-context capabilities, achieving 91.8% accuracy on the RULER benchmark, even with 1 million tokens, thanks to YaRN scaling.
- Quantized models with AutoRound are fully compatible with libraries like Transformers and vLLM, making deployment easier and faster.
- AutoRound allows these massive models to run in ultra-low precision (2–4 bits) while maintaining high accuracy, reducing memory usage, and inference cost.
- Mixed-precision models, like INT4 for expert layers and INT8 for non-expert layers, maintain a balance between efficiency and performance.
What Is Qwen3-Next-80B-A3B-Instruct?
Qwen3-Next-80B-A3B-Instruct features an 80 billion parameter model but activates only 3 billion parameters during inference, and is also called the next-generation foundation models. Qwen3-Next-80B-A3B introduces a Hybrid Attention architecture, a High-Sparsity Mixture-of-Experts (MoE) design, and Multi-Token Prediction (MTP), achieving significant improvements in throughput, cost efficiency, and long-context understanding. Let us understand each of these terms in a little more detail.
-
Hybrid Attention: Hybrid Attention combines different types of attention mechanisms to process information more efficiently. It enables the model to focus on both short-term details and long-range dependencies without compromising performance.
-
High-Sparsity Mixture-of-Experts (MoE): MoE divides the model into several smaller “expert” networks, and only a few are activated for each input. This means the model can handle large workloads while using fewer resources, improving speed and cost efficiency.
-
Multi-Token Prediction (MTP):
Instead of predicting one word at a time, MTP allows the model to predict multiple tokens in a single step. This increases the inference speed and makes text generation faster and more fluent.
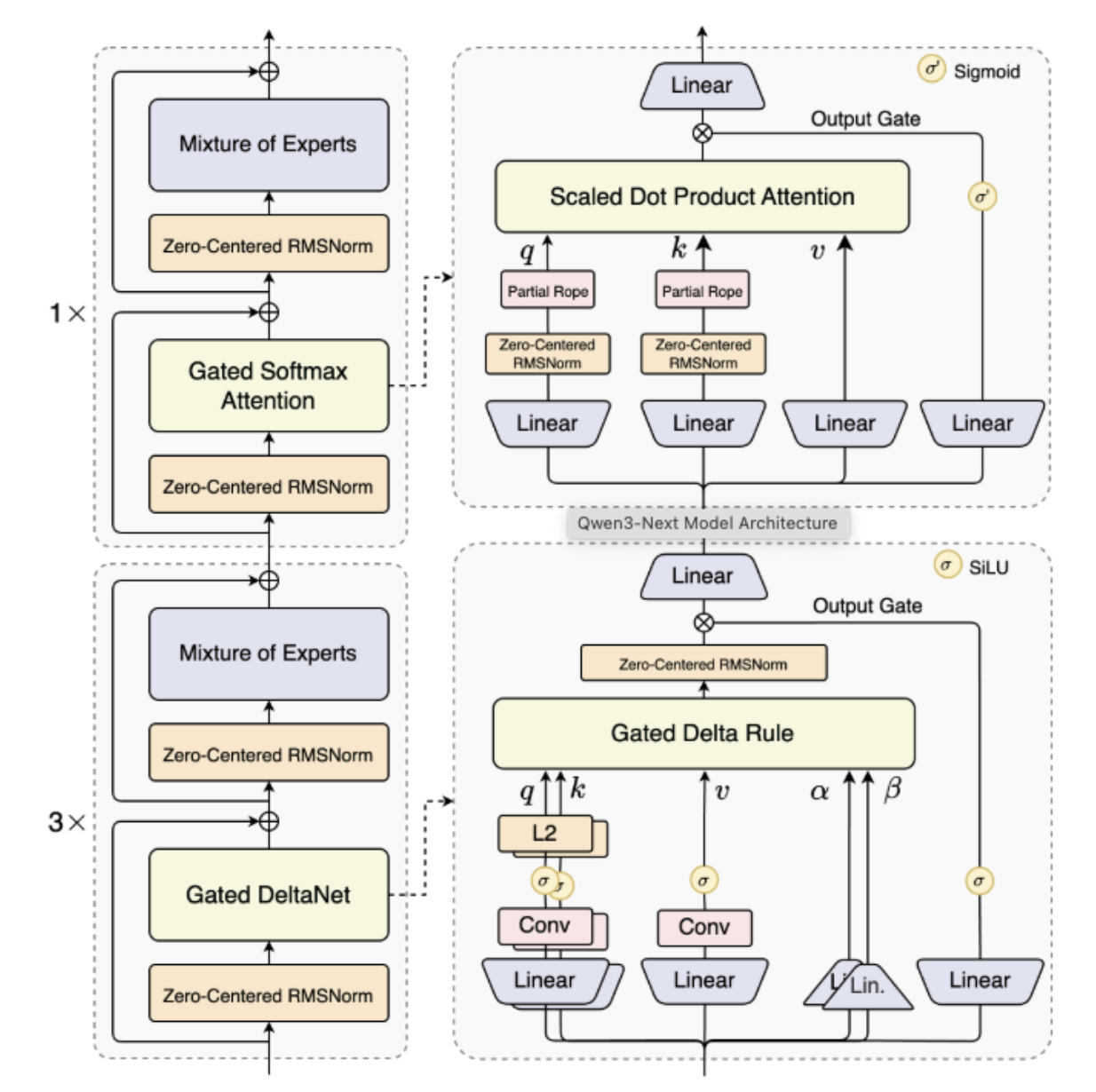
Key architectural stats:
- Total Parameters: 80B (3B active)
- Layers: 48
- Experts: 512 (10 activated + 1 shared)
- Context Length: 262,144 tokens (extendable up to 1 million tokens)
- Hidden Dimension: 2048
Key Innovations in Qwen3-Next
1. Hybrid Attention for Long-Context Modeling
Traditional transformers rely on dense attention, which scales quadratically with context length.
Qwen3-Next replaces it with Gated DeltaNet + Gated Attention, enabling efficient context modeling for ultra-long sequences.
This hybrid attention mechanism ensures:
- Linear or near-linear scaling for longer contexts.
- Stable training and better gradient propagation.
- Efficient handling of up to 256K tokens natively and 1M tokens with YaRN scaling.
2. High-Sparsity Mixture-of-Experts (MoE)
The model integrates high-sparsity MoE layers, activating only 10 out of 512 experts per token.
This leads to:
- Massive computational savings — lower FLOPs per token.
- Retention of large capacity through expert specialization.
Essentially, Expert Parallelism plays a vital role here, hence distributing experts across multiple GPUs, ensuring parallel efficiency without activating all parameters at once.
3. Multi-Token Prediction (MTP)
MTP enhances both pretraining efficiency and inference speed by allowing the model to predict multiple tokens simultaneously.
This is especially beneficial for:
- Reducing latency in text generation.
- Boosting throughput for inference tasks in large-scale deployments.
While MTP isn’t fully supported in Hugging Face Transformers yet, dedicated frameworks like SGLang and vLLM already implement it for improved serving efficiency.
4. Stability Optimizations
Qwen3-Next incorporates zero-centered and weight-decayed layer normalization, among other stability improvements.
These ensure:
- Better convergence during pretraining.
- Reduced risk of exploding gradients.
- Improved robustness for both pre-training and post-training stages.
Performance Highlights
Qwen3-Next-80B-A3B-Instruct demonstrates impressive benchmark performance, rivaling much larger models like Qwen3-235B, while offering 10x inference throughput for contexts exceeding 32K tokens.
| Benchmark | Qwen3-32B | Qwen3-235B | Qwen3-Next-80B |
|---|---|---|---|
| MMLU-Pro | 71.9 | 83.0 | 80.6 |
| GPQA | 54.6 | 77.5 | 72.9 |
| AIME25 | 20.2 | 70.3 | 69.5 |
| LiveCodeBench v6 | 29.1 | 51.8 | 56.6 |
| Arena-Hard v2 (GPT-4.1 eval) | 34.1 | 79.2 | 82.7 |
On the RULER Long-Context Benchmark, Qwen3-Next scored an impressive 91.8% average accuracy, showing that it can handle very long pieces of text without losing focus or accuracy. Even when processing up to 1 million tokens (which is like reading a huge document), the model stays consistent thanks to a method called YaRN scaling, which helps it manage and remember long contexts efficiently.

How to Use Qwen3-Next-80B-A3B-Instruct
Installation
Ensure the latest version of Hugging Face Transformers is installed:
pip install git+https://github.com/huggingface/transformers.git@main
Quickstart Example
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, dtype="auto", device_map="auto")
prompt = "Give me a short introduction to large language models."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=512)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Agentic Capabilities with Qwen-Agent
Qwen3’s agentic potential shines through tool calling.
You can integrate it with Qwen-Agent, which simplifies tool management using the Model Context Protocol (MCP) configuration.
Example:
from qwen_agent.agents import Assistant
llm_cfg = {
'model': 'Qwen3-Next-80B-A3B-Instruct',
'model_server': 'http://localhost:8000/v1',
'api_key': 'EMPTY',
}
tools = [
{'mcpServers': {
'time': {'command': 'uvx', 'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']},
"fetch": {"command": "uvx", "args": ["mcp-server-fetch"]}
}},
'code_interpreter',
]
bot = Assistant(llm=llm_cfg, function_list=tools)
messages = [{'role': 'user', 'content': 'Summarize the latest Qwen3-Next advancements.'}]
for responses in bot.run(messages=messages):
pass
print(responses)
Processing Ultra-Long Contexts with YaRN
Qwen3-Next natively supports 262K tokens, but can extend to 1M tokens using YaRN (Yet Another RoPE Normalization) scaling.
Add the following to your config.json:
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 262144
}
Or via CLI for vLLM:
vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}'
YaRN ensures stable attention patterns even in extremely long contexts, making it ideal for document analysis, codebases, or agent memory tasks.
Qwen3-Next-80B-A3B-Instruct-int4-AutoRound
The Qwen3-Next-80B-A3B-Instruct INT4 mixed model is a quantized version of the original Qwen3-Next-80B-A3B-Instruct. The model has been optimized with INT4 precision for expert layers with group size 128 and symmetric quantization, while non-expert layers fall back to 8-bit. This process has drastically reduced the model’s size, thus making the model faster, efficient, and also cheaper to run.
This mixed-precision setup reduces memory usage and speeds up inference without changing the model’s behavior. The quantization was generated automatically via Intel’s AutoRound (RTN), with no algorithm tuning applied.
What is AutoRound in Model Quantization?
AutoRound is a tool that helps make large AI models, like language or vision-language models, much smaller and faster by reducing the number of bits used to store their weights (quantization) sometimes down to 2–4 bits.
In simple terms:
- It compresses models so they take less memory and compute, while still keeping their predictions accurate.
- AutoRound uses smart techniques like sign-gradient descent to do this automatically, with minimal tuning needed.
- It works on a variety of hardware and integrates with popular libraries like Transformers and vLLM, making it easy to run these smaller, faster models in real applications.
Essentially, AutoRound lets huge AI models run more efficiently without losing much of their “brainpower.”
Qwen3-Next-80B on DigitalOcean Droplets
In this guide, we’ll walk through the steps to set up and run the Qwen3-Next-80B-A3B-Instruct-int4-mixed-AutoRound model on a Droplet. This quantized version of the Qwen3-Next model is optimized for faster inference and smaller memory usage hence, this model can be a practical choice even for CPU-based testing.
Step 1: Log in to DigitalOcean and Create a Droplet
First, log in to your DigitalOcean account and create a Droplet with specifications that meet your project’s needs.
This Droplet will serve as your cloud environment for running the model.
Step 2: Create a Virtual Environment
Creating a virtual environment keeps your dependencies clean and isolated.
python3 -m venv venv
source venv/bin/activate
→ This ensures that the Python packages you install don’t conflict with system-level packages.
Step 3: Install Required Dependencies
Next, install PyTorch, Hugging Face Transformers, Accelerate, and Hugging Face Hub.
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install git+https://github.com/huggingface/transformers
pip install git+https://github.com/huggingface/accelerate
pip install huggingface_hub
→ These libraries provide the tools to load, manage, and run large language models efficiently.
Step 4: Authenticate with Hugging Face
Log in to your Hugging Face account to access the model repository.
hf auth login
→ Paste your Hugging Face access token when prompted.
Step 5: Load the Model and Tokenizer
Now, let’s download and initialize the Qwen3-Next-80B-A3B-Instruct-int4-mixed-AutoRound model and its tokenizer.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Intel/Qwen3-Next-80B-A3B-Instruct-int4-mixed-AutoRound"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto",
)

→ This code automatically loads the quantized model and maps it to the available device (CPU or GPU).
Note: The quantized model has 9 shards, compared to 41 shards in the original 80B model, making it much lighter to load and run.
Step 6: Test the Model for Inference
Once the model is ready, you can test it by generating text responses.
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
"""
content: A large language model (LLM) is a type of artificial intelligence system trained on vast amounts of text data to understand and generate human-like language. These models, such as GPT, PaLM, or LLaMA, use deep learning architectures—typically based on the transformer network—to predict the next word in a sequence, enabling them to answer questions, write essays, translate languages, and even code. LLMs learn patterns, context, and relationships in language without explicit programming, making them versatile tools for a wide range of natural language tasks. Their scale—often with billions or trillions of parameters—allows them to capture nuanced linguistic features, though they also require significant computational resources and raise important ethical and safety considerations.
"""
The quantized AutoRound version performs decently on CPU, thus making it ideal for local testing, though optimal results can be achieved when running on a GPU.
FAQ’s
1. What makes Qwen3-Next-80B-A3B-Instruct different from other LLMs? It combines Hybrid Attention, Mixture-of-Experts, and Multi-Token Prediction to handle very long contexts efficiently, offering faster and more cost-effective inference.
2. What is Hybrid Attention? Hybrid Attention mixes different attention mechanisms to focus on both short- and long-range information in the text, improving the model’s understanding of context.
3. What is High-Sparsity Mixture-of-Experts (MoE)? MoE divides the model into smaller expert networks and only activates a few for each input, saving computation and memory while keeping performance high.
4. What is Multi-Token Prediction (MTP)? MTP allows the model to predict multiple words at once instead of one at a time, speeding up text generation.
5. What is YaRN scaling? YaRN scaling helps the model manage extremely long sequences by improving how it keeps track of token positions, enabling stable performance even with millions of tokens.
6. What is AutoRound? AutoRound is a quantization tool that compresses large models to low-bit formats (2–4 bits) while keeping accuracy high, making them faster and less memory-intensive.
7. How do mixed-precision models work?
In mixed-precision setups, expert layers use lower precision (e.g., INT4) and non-expert layers use slightly higher precision (e.g., INT8) to balance efficiency and performance.
Conclusion
Qwen3-Next-80B-A3B-Instruct is a significant step in building efficient models. Its variant, Qwen3-Next-80B-A3B-Instruct-int4-mixed-AutoRound, demonstrates how quantization can make these large models more accessible without compromising on performance. Qwen-Next series has shown how models can handle longer context while maintaining accuracy. Also, the quantized version has allowed to use these models to be more practical by reducing the memory and computational requirements.
Running these models on Droplets adds another layer of convenience, allowing developers and researchers to quickly set up high-performance environments without the need to set up a complex infrastructure.
With the right tools and platforms, anyone can explore large-scale AI, test new ideas, and create exciting applications that push the limits of what AI can understand and do with language.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.